虽然美国读研究生的时候,一个很头疼的问题就是阅读科学文献。原因很多,但是其中一个就是文献里面有许多单词不知道意思,这就时不时地要查字典。到后来情况就逐渐变好了,但是在接触到新的领域的时候,又出现一些该领域的新词汇,又要学习这些单词。当时我想,如果有个工具可以自动把文献翻译成汉语就好了。
随着人工智能在翻译领域的进展,长句子的准确翻译变为可能。当然,与“信达雅”还是差距很大,不过通过一些例子感觉已经是达到“信”了,“达”也初步达到了。或许以后还可以“雅”。对科研人来讲,能够“信”其实就已经很好了,毕竟对英文也不是一点都不懂。
看到技术成熟,我们就给Stork(文献鸟)增添了高级功能:翻译!当Stork给我发邮件的时候,邮件里的文献已经翻译好了:
![]()
这样我就可以快速浏览文献,省不少时间。
打开某个文献,里面的摘要也翻译了:
![]()
总体感觉翻译得还不错,比普通的逐字翻译要好很多,可以作为阅读的辅助功能。
该功能是付费功能。如果感兴趣的话,可以参考下面页面的操作:
https://www.storkapp.me/translation.html
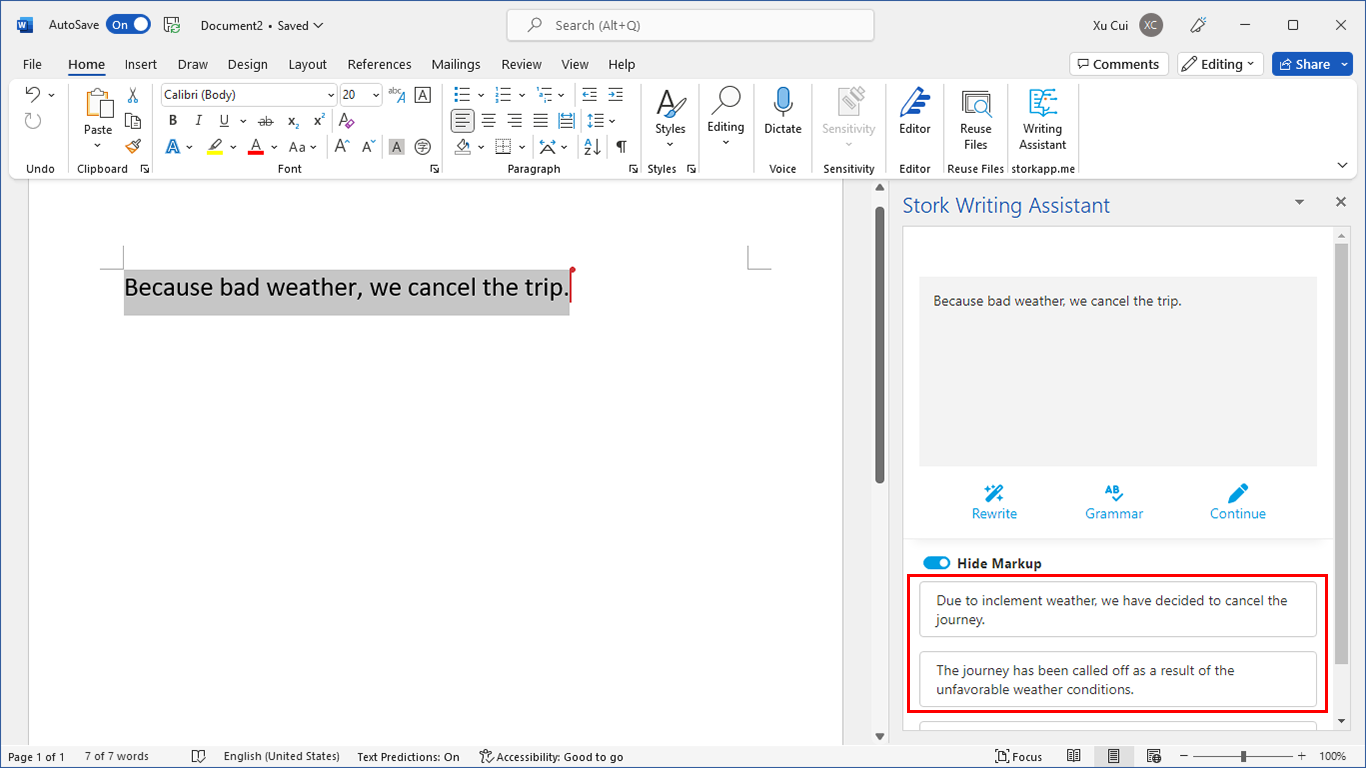
写作助手,把中式英语变成专业英文
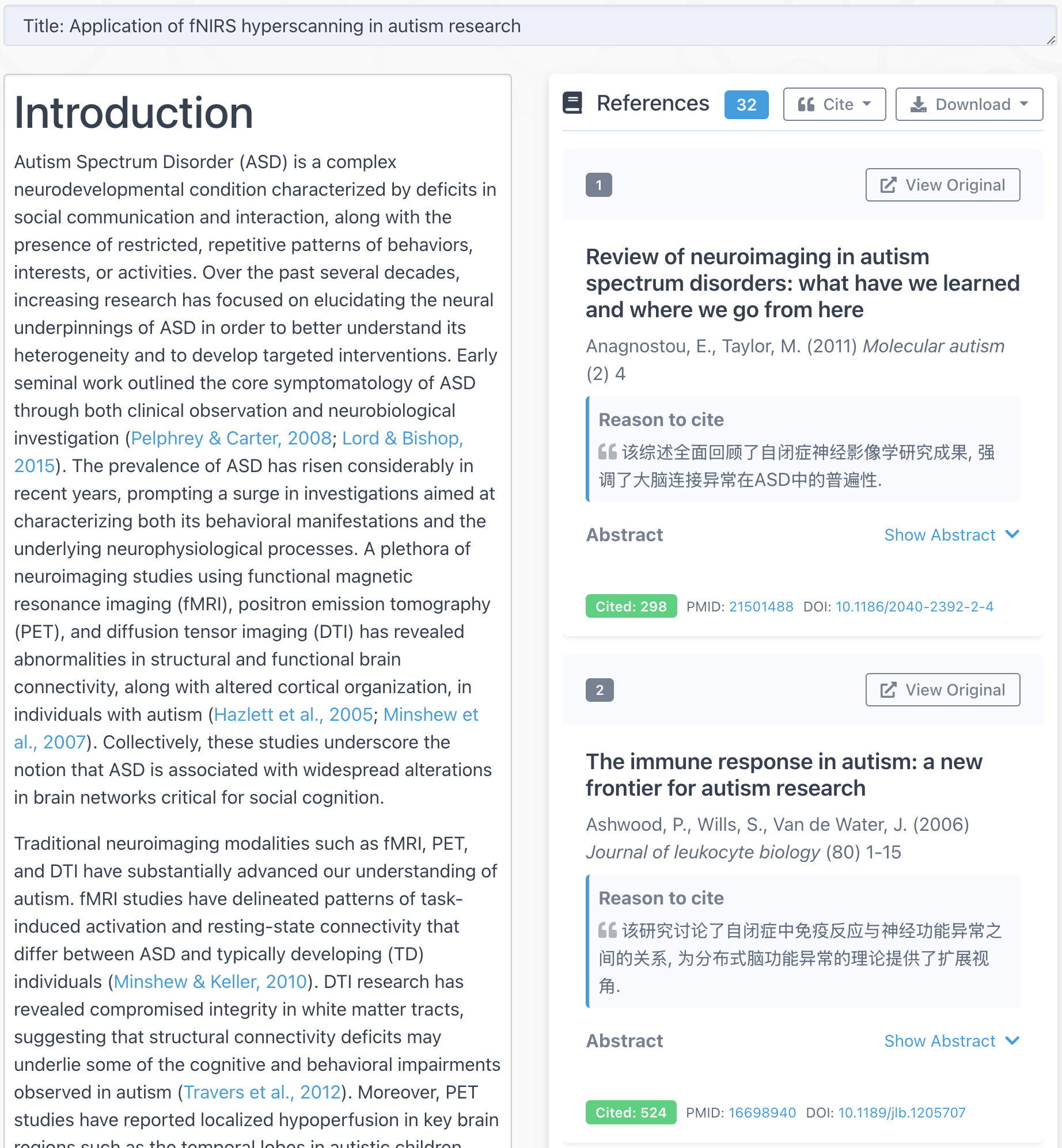
AI writing papers with real references
Stork真的是非常棒的一款文献和基金的追踪工具!但是期刊的影响因子似乎没有每年在更新,请问如何操作可以看到最新的影响因子?或者,很期待以后可以看到这方面的完善~
@warrenyang
我们最近刚刚更新了影响因子,是不是还有老的?您能不能发个例子?
现在影响因子是最新的了,谢谢!
膜拜一下创始人。